Articles de blog / Mesurer la qualité de la recherche d’information en santé
Points de vue
Nos solutions
Mesurer la qualité de la recherche d’information en santé

Écrit par Clinia
Publié 2026-03-03

Lorsqu’on saisit une requête dans une barre de recherche, l'objectif parait simple : trouver les informations les plus pertinentes, voire les plus exactes. Mais derrière cette apparente simplicité se cache une question complexe à laquelle tous les scientifiques, ingénieurs et chercheurs spécialisés en données sont tôt ou tard confrontés : comment mesurer la « pertinence » ou l'« adéquation » ?
Dans le domaine de la recherche d'information (en anglais, Information Retrieval ou IR), la science qui vise à créer des systèmes capables de retrouver des documents pertinents, cette question a une longue et riche histoire. Au fil des années, ce domaine a développé un arsenal complet de mesures pour évaluer les performances de recherche : précision, rappel, F-mesure, NDCG, mAP, pour ne citer que les principales. Chacun de ces indicateurs offre une perspective différente de la qualité. Le fonctionnement des indicateurs de classement, tels que le gain cumulatif actualisé (NDCG), ainsi que leur justification théorique, est décrit dans les références fondamentales en recherche d’information [1]. Dans de nombreux domaines (commerce électronique, information, divertissement), ils fonctionnent très bien.
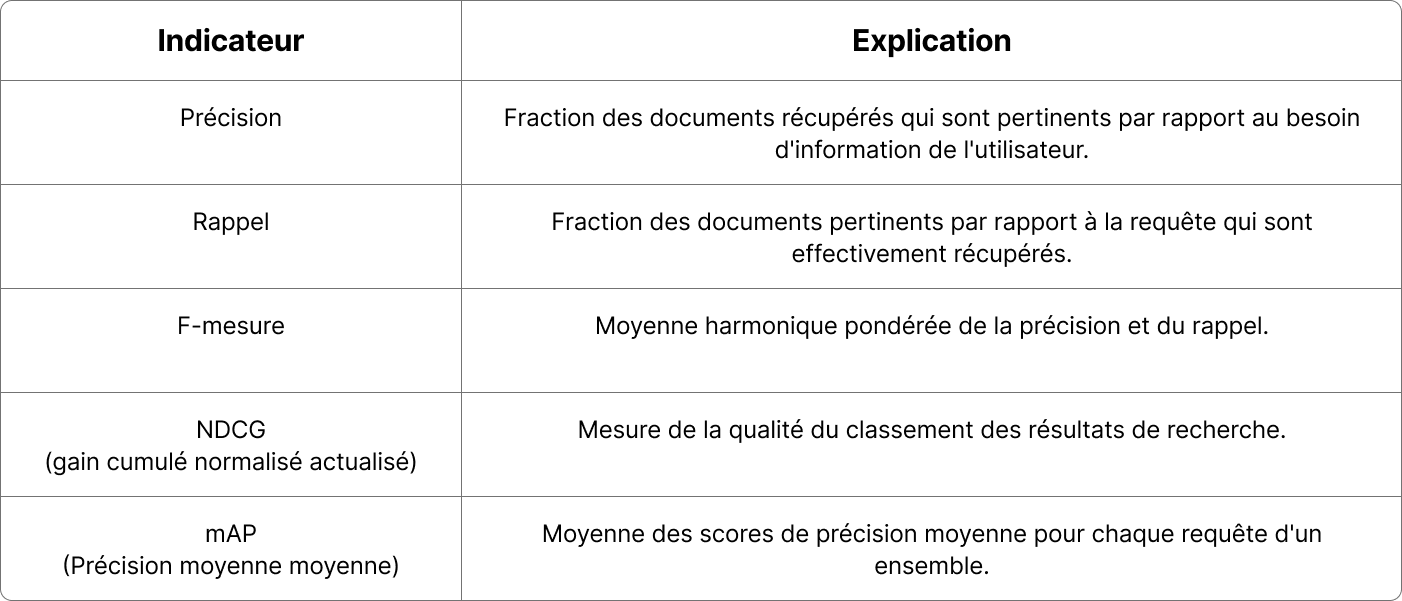
Indicateurs de recherche courants
Mais dans le domaine de la santé, la situation est différente. Dans le cadre de la recherche dans les dossiers patients, par exemple, chaque requête, chaque note récupérée, chaque document manqué peut avoir des conséquences concrètes. L'optimisation d'une mesure inappropriée ne fausse pas seulement le score de performance, elle peut fausser la prise de décision clinique elle-même.
Chez Clinia, nous concevons des systèmes de recherche adaptés au secteur de la santé. Cela signifie que nous devons repenser ce que nous mesurons, pourquoi, et comment la signification même de la pertinence évolue dans un contexte clinique et selon les cas d’usage spécifiques.
Les indicateurs façonnent les comportements : ce que nous mesurons détermine ce que les systèmes apprennent à optimiser. Dans le domaine de la santé, ces mesures doivent être conçues en collaboration avec des cliniciens et des chercheurs, en plaçant le jugement humain au cœur du processus de formation et d’évaluation des algorithmes.
Dans la recherche traditionnelle, l'objectif est la qualité du classement, c'est-à-dire de s'assurer que les résultats les plus pertinents apparaissent en tête de liste. Des mesures telles que le NDCG@k récompensent cette approche en mettant l'accent sur la pertinence graduée et le positionnement précoce [7].
La recherche d'informations cliniques fonctionne toutefois selon des contraintes différentes. Dans le cas des dossiers patients, les cliniciens se soucient moins de l'endroit où les informations apparaissent que du fait qu'elles soient trouvées. Une note enfouie concernant un traitement antérieur peut être aussi importante qu'un document en tête de liste.
Imaginez un clinicien cherchant dans un dossier médical électronique des « réactions allergiques passées à la pénicilline ». Un système optimisé pour le classement pourrait afficher des notes récentes, mais non pertinentes sur les antibiotiques, tandis qu'une approche axée sur le rappel garantit qu'un ancien résumé de sortie documentant une éruption cutanée ne sera pas oublié, même s'il est enfoui loin dans le dossier. En médecine, ce qui importe, ce n'est pas seulement de trouver certaines informations pertinentes, mais de garantir qu'aucune information critique ne soit négligée.
Cette distinction révèle les limites des mesures standards et la nécessité de privilégier le rappel, qui mesure l'exhaustivité (= combien de documents pertinents sont récupérés), par rapport aux mesures basées sur le classement comme NDCG@k [2].
Dans les domaines où la sécurité est cruciale, les risques sont asymétriques. Un courriel légitime filtré à tort et un résultat de laboratoire critique non récupéré sont des erreurs structurellement similaires, mais leurs conséquences diffèrent considérablement. En santé, l'absence d'informations pertinentes peut avoir une incidence directe sur la sécurité des patients, et cette omission peut passer inaperçue. Dans de tels contextes, les défaillances les plus graves sont souvent celles qui sont invisibles, c’est-à-dire jamais récupérées.
Contrairement à de nombreuses tâches sur le Web, la pertinence clinique est intrinsèquement contextuelle et temporelle. La note la plus utile pour un clinicien peut être la plus récente mentionnant un état, ou la plus ancienne documentant une apparition, selon la question posée. Les mesures traditionnelles de recherche d’information traitent généralement la pertinence comme une étiquette statique, mais en médecine, la pertinence est dynamique : elle évolue avec le temps et selon la question clinique. Chaque diagnostic, chaque analyse et chaque traitement n'ont de sens que dans le contexte du moment où ils sont produits. Des travaux récents démontrent que l'intégration d'une structure temporelle dans les modèles de dossiers médicaux électroniques permet d'obtenir des représentations plus précises et plus fiables du parcours de soins des patients [5] (voir également notre récente analyse).
Les connaissances médicales sont vastes, mais inégalement réparties. Les affections, traitements et symptômes courants dominent les textes et les ensembles de données médicaux, tandis que les maladies rares, les présentations atypiques et les interactions peu fréquentes forment une queue longue (en anglais, long tail) de connaissances peu fréquentes, mais cliniquement importantes. Les systèmes de recherche traditionnels et les grands modèles linguistiques apprennent et s'optimisent souvent autour de cette « tête » d'informations fréquentes, fonctionnant bien pour les cas courants, mais peinant à représenter les cas rares.
Des travaux récents dans le domaine de la recherche d'information ont souligné l'importance des connaissances de la queue longue : des informations qui apparaissent rarement pendant l’entrainement, mais qui peuvent être cruciales pour un raisonnement précis et une aide à la décision [6]. En santé, négliger ces concepts peu fréquents peut entrainer des lacunes dans les systèmes de recherche, où des preuves rares, mais essentielles peuvent être manquées. Un moteur de recherche clinique vraiment efficace doit donc dépasser l'optimisation des termes les plus fréquents pour se concentrer sur l'identification et la mise en avant de ces connaissances rares, mais critiques.
Dans le domaine des soins de santé, la qualité de la recherche dépend de la tâche à accomplir. Un système conçu pour l'identification des cohortes de patients peut privilégier l'exhaustivité, afin de s'assurer qu'aucun patient éligible ne soit oublié. En revanche, un outil de synthèse des dossiers médicaux doit mettre l'accent sur la précision et la clarté, en ne présentant que les informations qui reflètent fidèlement l'état du patient. Pour l'aide à la décision au point de service, la qualité peut être mesurée par la rapidité et la confiance avec lesquelles les cliniciens trouvent ce dont ils ont besoin.
Chaque tâche ayant son propre profil de risque et sa propre définition de la pertinence, les indicateurs d'évaluation ne peuvent être uniformes. Les indicateurs ne sont pas neutres : ils façonnent le comportement du système en déterminant ce qui est optimisé et ce qui peut être négligé. Lorsqu'ils ne sont pas alignés, les systèmes peuvent obtenir de bons résultats sur les tests de performance, mais échouer en pratique.
Chez Clinia, nous veillons à ce que les principes de recherche que nous adoptons soient adaptés à nos différents cas d’usage et aux exigences spécifiques des soins de santé qu’ils servent. En fondant notre approche à la fois sur la rigueur scientifique et sur les besoins du terrain, nous visons à rendre la recherche non seulement performante, mais aussi cliniquement significative.
[1] Jeunen O, Potapov I, Ustimenko A. On (Normalized) discounted cumulative gain as an off-policy evaluation metric for top-n recommendation. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24); August 25–29, 2024; Barcelona, Spain. New York, NY: Association for Computing Machinery; 2024. doi:10.1145/3637528.3671687
[2] Sivarajkumar, S., et al. (2024). “Clinical Information Retrieval: A Literature Review.” Journal of Clinical Informatics.
[3] Chamberlin SR, Bedrick SD, Cohen AM, et al. Evaluation of patient-level retrieval from electronic health record data for a cohort discovery task. JAMIA Open. 2020;3(3):395-404. Published 2020 Jul 26. doi:10.1093/jamiaopen/ooaa026
[4] Haneuse S, Arterburn D, Daniels MJ. Assessing missing data assumptions in EHR-based studies: a complex and underappreciated task. JAMA Network Open. 2021;4(2):e210184. doi:10.1001/jamanetworkopen.2021.0184
[5] Cui H, Unell A, Chen B, et al. TIMER: temporal instruction modeling and evaluation for longitudinal clinical records. npj Digital Medicine. 2025;8:577. doi:10.1038/s41746-025-01965-9
[6] Li D, Yan J, Zhang T, Wang C, He X, Huang L, Xue H, Huang J. On the role of long-tail knowledge in retrieval augmented large language models. arXiv [cs.IR]. Published June 24, 2024. Available from: https://arxiv.org/abs/2406.16367
[7] Mondal S. Normalized discounted cumulative gain (NDCG) – the ultimate ranking metric: NDCG – the rank-aware metric for evaluating recommendation systems. Towards Data Science. October 15, 2024. Accessed October 24, 2025. https://towardsdatascience.com/

