Blog Articles / Rethinking How We Measure Search Quality in Healthcare
Insights
Our Solutions
Rethinking How We Measure Search Quality in Healthcare

Written by Clinia
Published 2026-03-03

When you type a query into a search bar, the goal seems simple: to find the most relevant if not the most critical, information. But behind that simplicity lies a complex question that every data scientist, engineer, and researcher eventually faces: how do you measure “right”, “critical” or “relevant”?
In information retrieval (IR)—the science of building systems that fetch relevant documents—this question has a long and rich history. Over the years, the field has developed an arsenal of metrics to evaluate retrieval performance: precision, recall, F-score, NDCG, and mAP to name the main ones. Each of these metrics tells a different story about quality. The canonical formulation and motivation for ranking-oriented metrics such as discounted cumulative gain (and its normalized form, NDCG) are laid out in classic IR work [1]. And in many domains—like e-commerce, news, or entertainment—they work just fine.
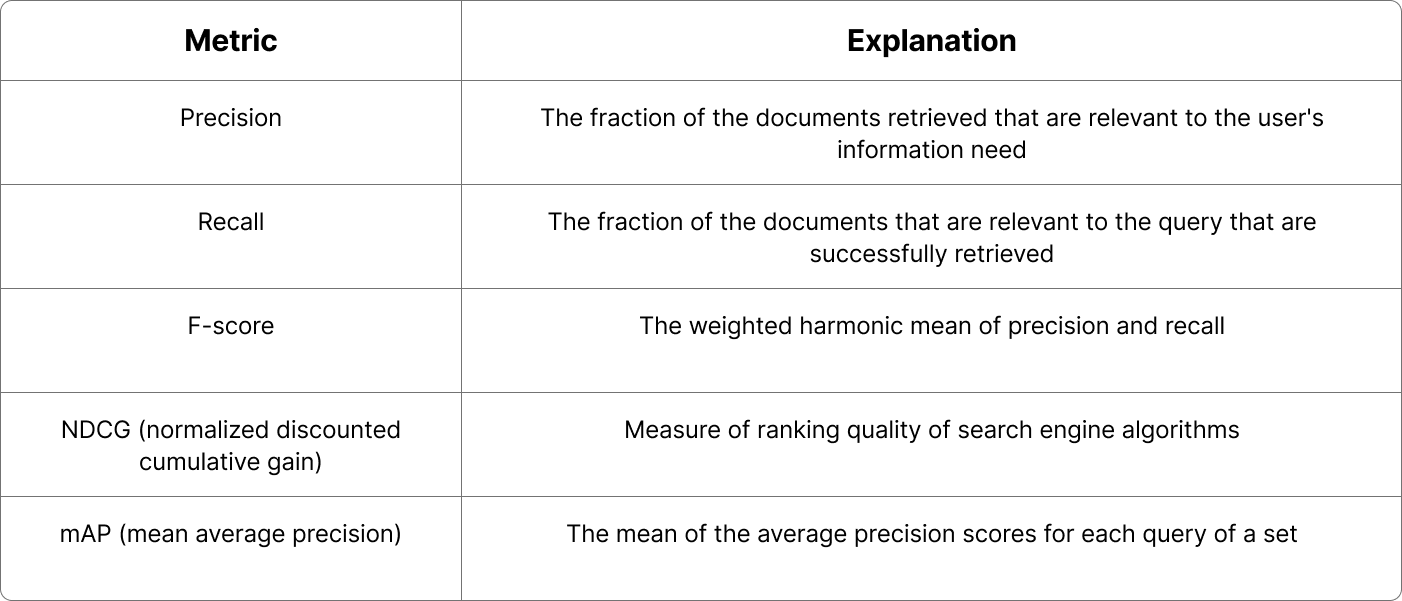
Common retrieval metrics
But in healthcare, the story changes. In patient chart search, for instance, every query, every retrieved note, every missed document can have real-world consequences. Optimizing for the wrong metric doesn’t just distort the performance score, it can even distort clinical decision-making itself.
At Clinia, we design health-grade retrieval systems. That means we need to rethink what we measure, why we measure it, and how the meaning of relevance itself changes in a clinical context and across specific use cases.
Metrics shape behavior: what we measure determines what systems learn to optimize. In healthcare, these measurements must be co-designed with clinicians and researchers, embedding human judgment at the core of how algorithms are trained and assessed.
In traditional search, the goal is ranking quality—ensuring that the most relevant results appear near the top. Metrics such as NDCG@k reward this by emphasizing graded relevance and early positioning [7].
Clinical information retrieval, however, operates under different constraints. When searching through patient records, clinicians care less about where information appears and more about whether it is found at all. A buried note about a prior treatment can be as critical as a top-ranked document.
Imagine a clinician searching an electronic health record for “past allergic reactions to penicillin.” A ranking-optimized system might surface recent but irrelevant notes about antibiotics, while a recall-oriented approach ensures that an older discharge summary documenting a rash isn’t missed, even if it’s buried deep in the record. In medicine, what matters is not just finding some relevant information but ensuring that no critical information is overlooked.
This distinction reveals the limits of standard IR metrics and the need to prioritize recall, which measures completeness (= how many relevant documents are retrieved) **over ranking-based metrics like NDCG@k [2].
In safety-critical domains, retrieval errors are asymmetrical risks. A legitimate email wrongly filtered and a critical lab result not retrieved are structurally similar errors, yet their consequences differ dramatically. In healthcare, missing relevant information can directly affect patient safety—and the omission may go unnoticed. In such contexts, the most consequential failures are often the invisible ones: the information that was never retrieved.
Unlike many web tasks, clinical relevance is inherently contextual and temporal. The most useful note for a clinician may be the most recent one mentioning a condition or the earliest note that documents an onset, depending on the question at hand. Traditional IR metrics typically treat relevance as a static label, but in medicine, relevance changes with time and with the specific clinical question. Every diagnosis, lab, and treatment makes sense only in the context of when it occurs. Recent work demonstrates that incorporating temporal structure into models of electronic health records leads to more accurate and reliable representations of patient care trajectories [5] (see also our recent insight).
Medical knowledge is vast but unevenly distributed. Common conditions, treatments, and symptoms dominate medical texts and datasets, while rare diseases, atypical presentations, and uncommon interactions form a long tail of infrequent yet clinically important knowledge. Traditional retrieval systems and large language models often learn and optimize around this “head” of frequent information, performing well on common cases but struggling to represent the rare ones.
Recent work in information retrieval has underscored the importance of long-tail knowledge: information that appears rarely during training but that can be crucial for accurate reasoning and decision support [6]. In healthcare, overlooking these low-frequency concepts can lead to knowledge gaps in retrieval systems, where uncommon but high-stakes evidence may be missed. A truly effective clinical search engine must therefore go beyond optimizing for the most frequent terms and focus on identifying and elevating these rare yet pivotal pieces of knowledge.
In healthcare, retrieval quality is task-dependent. A system designed for patient cohort identification may prioritize completeness, ensuring that no eligible patient is missed. In contrast, a chart summarization tool must emphasize precision and clarity, surfacing only information that accurately reflects a patient’s condition. For point-of-care decision support, quality may be measured by how quickly and confidently clinicians find what they need.
Because each task carries its own risk profile and definition of relevance, evaluation metrics cannot be one-size-fits-all. Metrics are not neutral; they shape system behaviour by determining what is optimized and what may be overlooked. When misaligned, systems can perform well on benchmarks yet fail in practice.
At Clinia, we ensure that the retrieval principles we adopt are adapted to our various use cases and to the specific demands of healthcare they serve. By grounding our approach in both scientific rigour and real-world use, we aim to make search not only performant but also clinically meaningful.
[1] Jeunen O, Potapov I, Ustimenko A. On (Normalized) discounted cumulative gain as an off-policy evaluation metric for top-n recommendation. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24); August 25–29, 2024; Barcelona, Spain. New York, NY: Association for Computing Machinery; 2024. doi:10.1145/3637528.3671687
[2] Sivarajkumar, S, et al. (2024). “Clinical Information Retrieval: A Literature Review.” Journal of Clinical Informatics.
[3] Chamberlin SR, Bedrick SD, Cohen AM, et al. Evaluation of patient-level retrieval from electronic health record data for a cohort discovery task. JAMIA Open. 2020;3(3):395-404. Published 2020 Jul 26. doi:10.1093/jamiaopen/ooaa026
[4] Haneuse S, Arterburn D, Daniels MJ. Assessing missing data assumptions in EHR-based studies: a complex and underappreciated task. JAMA Network Open. 2021;4(2):e210184. doi:10.1001/jamanetworkopen.2021.0184
[5] Cui H, Unell A, Chen B, et al. TIMER: temporal instruction modeling and evaluation for longitudinal clinical records. npj Digital Medicine. 2025;8:577. doi:10.1038/s41746-025-01965-9
[6] Li D, Yan J, Zhang T, Wang C, He X, Huang L, Xue H, Huang J. On the role of long-tail knowledge in retrieval augmented large language models. arXiv [cs.IR]. Published June 24, 2024. Available from: https://arxiv.org/abs/2406.16367
[7] Mondal S. Normalized discounted cumulative gain (NDCG) – the ultimate ranking metric: NDCG – the rank-aware metric for evaluating recommendation systems. Towards Data Science. October 15, 2024. Accessed October 24, 2025. https://towardsdatascience.com/

