Articles de blog / Créer une IA plus fiable en collaborant avec des experts
Points de vue
Nos solutions
Créer une IA plus fiable en collaborant avec des experts

Écrit par Clinia
Publié 2025-10-23

On ne compte plus les articles traitant de la manière dont l’IA peut assister les professionnels de la santé dans leur pratique, si ce n’est les remplacer complètement. En prenant le sujet sous un autre angle, nous souhaitons partager comment des praticiens et des linguistes nous ont aidés à développer des modèles d’IA et à améliorer nos expériences en récupération d’information médicale.
Chez Clinia, nous développons des solutions d’IA qui permettent aux professionnels de la santé et aux patients de trouver rapidement des informations médicales fiables, tirées à la fois de recommandations cliniques et d’articles scientifiques évalués par des pairs. Très tôt dans le processus, nous avons compris quelque chose de fondamental: pour construire des modèles d’IA fiables pour la recherche d’information en santé, nous ne pouvions pas compter uniquement sur les développeurs ML, linguiste NLP et ingénieurs qualité des données de notre équipe R&D. En d’autres termes, l’expertise technique ne suffit pas.
Pour construire des modèles fiables et solides, l’expertise médicale doit faire partie du processus dès le départ. C’est pourquoi nous avons intégré directement des praticiens (médecins généralistes, spécialistes et infirmières) dans le développement de nos modèles, non seulement comme consultants mais également comme annotateurs qui ont façonné les données sur lesquelles nos modèles s’entraînent.
De cette collaboration, nous avons tiré bien plus d’enseignements que prévu. Nous en présentons quelques dans cet article.
Pour un non-professionnel, diabète de type 1 vs. diabète de type 2, pneumonie virale vs. pneumonie bactérienne, ou AVC ischémique vs. AVC hémorragique ne sont que des paires d’étiquettes similaires. Pour un professionnel de santé, ces distinctions correspondent à des parcours de soins très différents. Sans expertise clinique, une réponse à une requête médicale peut sembler techniquement correcte tout en passant à côté des réalités pratiques du diagnostic et du traitement.
Lorsque nous utilisons le terme AVC, il fait généralement référence à un AVC ischémique, qui représente environ 90 % des cas aux États-Unis, selon Healthline (19 mai 2023). Les autres types, comme les AVC hémorragiques, représentent environ 10 % des cas.
La plupart du temps, un annotateur non spécialiste (ou un modèle générique) qui ne connaît que le premier type d’AVC pourrait valider à tort que la requête suivante peut trouver une réponse satisfaisante dans le passage ci-dessous:

Le passage incorrect se concentre de manière trop étroite sur les seuils de tension artérielle pour la thrombolyse dans l’AVC ischémique aigu, sans aborder les objectifs de tension artérielle à long terme recommandés pour les survivants d’AVC ni les stratégies de prise en charge distinctes selon le type d’AVC (ischémique vs hémorragique). Un médecin reconnaîtrait que la question concerne l’objectif global de tension artérielle après un AVC, et pas seulement l’éligibilité à la thrombolyse. En ne présentant que les protocoles pour l’AVC ischémique aigu, le passage est trompeur: il pourrait amener quelqu’un à appliquer ces règles au traitement chronique ou à d’autres types d’AVC, ce qui peut être dangereux et cliniquement inapproprié. En résumé, le passage ne distingue pas la gestion aiguë vs la gestion à long terme ni les sous-types d’AVC, ce qui en fait une réponse peu fiable à la question.
Seul un professionnel de la santé peut déterminer si un raisonnement tient vraiment, tant sur le plan de l’exactitude que de la pertinence clinique. En travaillant avec des médecins, nous avons appris à concevoir un cadre d’annotation qui respecte le raisonnement médical.
L’une de nos toutes premières tâches avec les annotateurs médicaux a été de construire un jeu de données de paires question–passage où le passage est jugé pertinent pour répondre à la question. Nous avons demandé aux médecins de lire des articles qu’ils consulteraient naturellement dans leur pratique pour approfondir leur connaissances sur un sujet, et d’écrire des questions auxquelles certains passages de ces articles pouvaient répondre.
Pour la plupart d’entre eux, le premier réflexe était de rédiger des questions très simples reprenant exactement les mots du passage, par exemple:
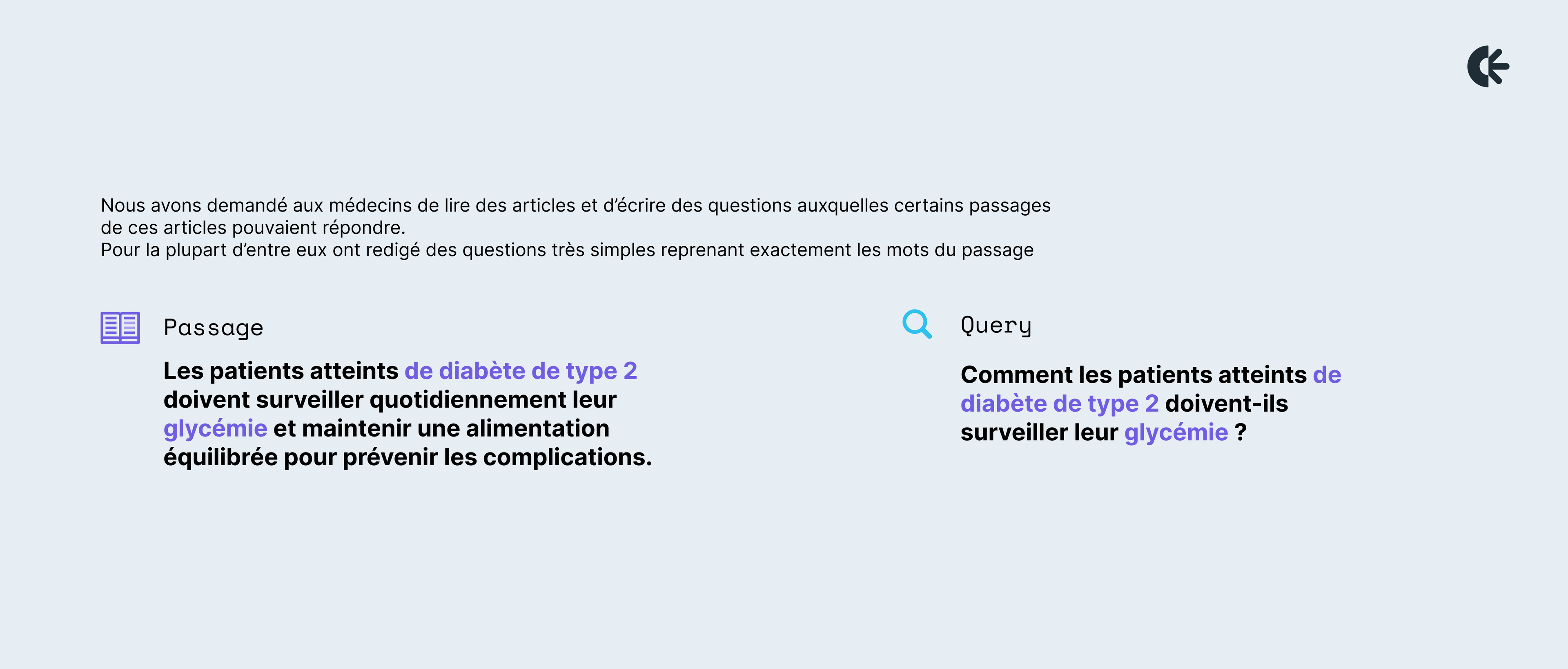
Très vite, nous avons constaté que ces passages ne représentaient aucun véritable défi et pouvaient être résolus avec de simples méthodes de correspondance de mots-clés. Pour construire des modèles plus avancés, nous devions aller plus loin.
Lors d’une deuxième itération, au lieu de répéter les mots exacts, nous avons demandé aux annotateurs de complexifier les requêtes en utilisant au moins des synonymes (termes équivalents), hyperonymes (termes plus généraux) ou hyponymes (termes plus spécifiques) dans les paires question–passage.

Nous avons réalisé que ces deux premières itérations pouvaient être gérées par nos annotateurs linguistes. Pour véritablement défier le système, nous avions besoin d’associations que seuls les médecins (et les modèles avancés) pouvaient accomplir.
Dans une troisième itération, nous avons élevé le niveau d’exigence en concevant des questions nécessitant raisonnement et inférence. Le modèle devait relier les indices de la requête au passage en faisant des inférences qui ne peuvent être confirmés que par un médecin.

Seul un professionnel médical peut confirmer que cette chaîne de raisonnement est exacte et cliniquement appropriée.
La constitution de jeux de données cliniques de haute qualité a nécessité à la fois des linguistes et des annotateurs médecins, mais nous avons rapidement constaté qu’ils excellent dans des aspects différents de la tâche. Les médecins ont la connaissance médicale, mais l’annotation demande un ensemble de compétences spécifiques: jongler avec le texte, les relations sémantiques et des tâches auxquelles ils ne sont pas habitués. Les linguistes, en revanche, savent créer des questions nuancées et reconnaître les relations sémantiques, mais n’ont pas les connaissances cliniques pour vérifier l’exactitude médicale. Au départ, cette lacune représentait un défi, mais avec le temps, nous avons appris à tirer parti des deux expertises en scindant l’évaluation des passages en deux dimensions: qualité linguistique et précision médicale. Nous avons notamment appliqué cette double approche lors de l’évaluation de réponses génératives.
Les linguistes se sont concentrés sur la création et l’évaluation des requêtes en termes de clarté, de nuance, de concision et de rigueur sémantique, tandis que les médecins validaient l’exactitude clinique des passages et des réponses. Cette stratégie nous a permis de combiner précision linguistique et fiabilité médicale, garantissant que nos jeux de données soient à la fois exigeants et fiables.
L’une des leçons les plus importantes a été de réaliser que l’implication des médecins va bien au-delà de l’amélioration des jeux de données. Leurs perspectives ont fondamentalement influencé notre approche: en façonnant la manière dont nous définissons les critères d’évaluation des modèles, déterminons ce qui constitue un résultat pertinent et considérons l’expérience de l’utilisateur final.
La valeur ne réside pas dans le simple fait que les médecins expliquent la médecine ou que les ingénieurs expliquent l’IA, mais dans une collaboration véritable: remettre en question les hypothèses, affiner les méthodes et itérer ensemble. Ce processus a façonné non seulement nos données, mais également l’ensemble de notre méthodologie de développement de modèles. Les médecins ont raison d’exiger des standards rigoureux pour l’IA. Construire cette confiance nécessite une transparence sur les limites des modèles, une écoute attentive des retours, ainsi qu’une ouverture totale dans notre travail. C’est cette confiance même qui a permis une collaboration réellement significative et qui sera essentielle pour l’adoption de ces outils en pratique clinique.
Les bénéfices de cette collaboration sont mutuels: pour les cliniciens, créer un outil qui fournit rapidement des réponses fondées sur des preuves et dignes de confiance est innovant et répond à un besoin longtemps insatisfait. Pour les linguistes, travailler sur un projet de recherche d’information permet de comprendre comment les modèles sont entraînés, quelles données ils nécessitent, et comment leur expertise linguistique peut directement améliorer la précision, la clarté et la nuance des modèles. Voir à quel point leurs retours sont pris en compte et intégrés de manière effective a été très motivant pour qu’ils restent impliqués, comme l’a souligné l’une de nos annotatrices médicales.
En fin de compte, notre travail a montré que lorsque cliniciens et linguistes contribuent directement au développement des modèles, les résultats vont bien au-delà de meilleurs jeux de données: ils transforment entièrement l’approche de l’IA en santé, ce qui est essentiel pour créer des outils véritablement utiles aux professionnels et à leurs patients.


